




Meta hat mit der Veröffentlichung von Llama 3.1 ein neues Kapitel in der Welt der künstlichen Intelligenz aufgeschlagen. Mit diesem Modell setzt das Unternehmen seine Verpflichtung zu offen zugänglicher KI fort und bietet Entwicklern, Unternehmen und der globalen Gemeinschaft eine leistungsstarke Ressource zur Nutzung und Weiterentwicklung.
Mark Zuckerberg über die Bedeutung von Open Source
In einem offenen Brief erläutert Mark Zuckerberg, CEO von Meta, warum Open Source nicht nur für Entwickler, sondern auch für Meta und die gesamte Welt von Vorteil ist. Er betont, dass offene Systeme Innovationen fördern und sicherstellen, dass die Vorteile der KI nicht auf wenige Akteure beschränkt bleiben. Durch die Bereitstellung von offenen Modellen können mehr Menschen weltweit von den Möglichkeiten der KI profitieren.
Einführung von Llama 3.1 405B: Das erste Frontier-Level Open Source AI-Modell
Llama 3.1 405B stellt einen bedeutenden Fortschritt dar. Mit einer beispiellosen Flexibilität, Kontrolle und hochmodernen Fähigkeiten konkurriert es mit den besten geschlossenen Modellen auf dem Markt. Dieses Modell eröffnet der Gemeinschaft neue Arbeitsabläufe wie die Generierung synthetischer Daten und Modell-Distillation, die bisher in dieser Größenordnung im Open Source-Bereich nicht möglich waren.
Erweiterung der Llama-Modelle
Neben dem neuen 405B-Modell hat Meta auch verbesserte Versionen der 8B- und 70B-Modelle veröffentlicht. Diese Modelle unterstützen acht Sprachen und haben eine erweiterte Kontextlänge von 128K. Dadurch eignen sie sich hervorragend für fortschrittliche Anwendungsfälle wie die Zusammenfassung langer Texte, mehrsprachige Konversationsagenten und Coding-Assistenten. Entwickler können die Ausgaben der Llama-Modelle nutzen, um andere Modelle zu verbessern, was durch die aktualisierte Lizenz von Meta ermöglicht wird.
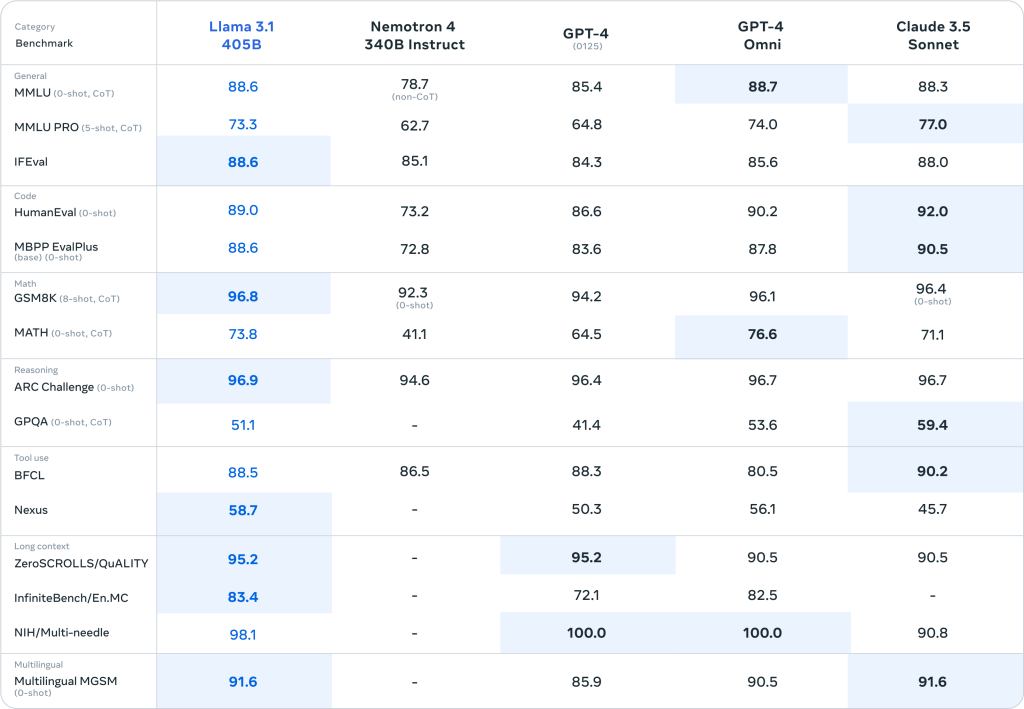
Umfangreiche Evaluierungen und hohe Leistungsfähigkeit
Die Leistungsfähigkeit von Llama 3.1 wurde auf über 150 Benchmark-Datensätzen in verschiedenen Sprachen getestet. Menschliche Evaluierungen in realen Szenarien zeigen, dass das 405B-Modell mit führenden Modellen wie GPT-4, GPT-4o und Claude 3.5 Sonnet konkurriert. Diese Ergebnisse unterstreichen die Stärke des neuen Modells in verschiedenen Aufgabenbereichen.

Architektur und Training des Modells
Llama 3.1 405B ist das bisher größte Modell von Meta und wurde mit über 15 Billionen Token trainiert. Um dies zu erreichen, hat Meta seine Trainingsinfrastruktur optimiert und das Modell auf über 16.000 H100-GPUs trainiert. Durch die Quantisierung von 16-Bit auf 8-Bit wurde der Rechenaufwand reduziert, sodass das Modell auf einem einzelnen Serverknoten betrieben werden kann.

Anwendungsfälle und Sicherheitsmaßnahmen
Mit Llama 3.1 405B hat Meta die Qualität der Antworten und die Fähigkeit zur detaillierten Anweisungsbefolgung verbessert. Das Modell wurde durch mehrere Runden der Feineinstellung und Datenoptimierung entwickelt, um sicherzustellen, dass es sowohl nützlich als auch sicher ist. Sicherheitswerkzeuge wie Llama Guard 3 und Prompt Guard wurden eingeführt, um eine verantwortungsbewusste Nutzung zu gewährleisten.
Ein wachsendes Ökosystem
Meta hat eine breite Palette von Partnern, darunter AWS, NVIDIA, Databricks, Groq, Dell, Azure, Google Cloud und Snowflake, die von Anfang an Dienstleistungen für Llama 3.1 anbieten. Entwickler können das Modell in den USA auf WhatsApp und auf meta.ai testen, indem sie herausfordernde mathematische oder Coding-Fragen stellen.